
Привет, дорогой читатель!
Сегодняшний пост я бы хотел начать со стандартного вопроса на собеседовании: “Какими достижениями на работе ты особенно гордишься?” Этот вопрос может удивить или даже оскорбить, ведь сегодня оказывается недостаточно просто хорошо выполнять свои обязанности, этим надо обязательно гордиться. Но не дай интервьюеру тебя застать врасплох. Если помещение просторное, то в этот момент лучше даже встать со стула, твой моноспектакль должен зажигать огонь в глазах. Обернул на днях метод в try / catch? Не стесняйся - ты уже предостерёг компанию от исключительной ситуации! Месяц назад исправил очередной баг? Это было не просто исправление, это было спасение компании от потенциального банкротства! И тут главное не перестараться, ведь интервьюер скорее всего тоже часто посещает собеседования, и уже не раз “спасал компанию от банкротства”. А лучше, конечно, заранее подготовиться к этому вопросу.
Но это стандартный вопрос. А мы вернёмся к нестандартному. В предыдущем посте мы уже познакомились с кэшированием и алгоритмом LRU вытеснения элементов. Предлагаю рассмотреть следующий пример:
В консоли мы увидим "Element 'x' was not found". Таким образом, из кэша будет вытеснен элемент x, к которому было в 100 раз больше обращений, но LRU стратегия никак это не учитывает. Этот пример хоть и достаточно искусственный, но он хорошо иллюстрирует ограничения LRU стратегии. В этом посте рассмотрим новую стратегию, которая будет учитывать частоту обращений к элементам. Поехали!
LFU (least frequently used) - стратегия вытеснения элемента, который использовался реже всего. Под данным элементом понимается элемент, доступ к которому по ключу (методы добавления и получения значения) осуществлялся наименьшее количество раз. В случае, если таких элементов несколько, то вытесняется элемент, доступ к которому не осуществлялся дольше всего.
Полную реализацию LFU кэша на C#, как всегда, можно посмотреть на GitHub проекта coding-interview.
Ну а мы вернёмся к реализации. Начнём с самого простого варианта. Реализуем обёртку вокруг ассоциативного массива без стратегии вытеснения:
Ограничим наш кэш максимально допустимым количеством элементов capacity. Создадим общий счётчик доступа к элементам totalAccessSteps, который будем увеличивать при каждом последующем доступе. Для каждого сохранённого элемента будем хранить время доступа к нему accessStepsByKey и количество обращений к данному элементу frequenciesByKey. Забегая вперёд отметим, что данная реализация не является оптимальной, в процессе она будет улучшена.
Обновим очевидные операции удаления элемента и очистки кэша:
Рассмотрим операцию добавления элемента в кэш. В зависимости от ситуации могут возникнуть три следующих случая:
- Если данный элемент присутствует в кэше, то обновляем его значение, количество обращений и время доступа;
- Если кэш содержит меньше элементов, чем его вместимость, то просто сохраняем новый элемент;
- Если кэш содержит уже максимально допустимое количество элементов, то удаляем элемент, который использовался наименьшее количество раз. Если таких элементов несколько, то удаляем элемент, доступ к которому осуществлялся раньше всего. После чего добавляем новый элемент.
Операция доступа к элементу по ключу также должна поменять время доступа и количество обращений к элементу, поэтому воспользуемся уже реализованным Update методом:
Как отмечалось выше, данная реализация не является оптимальной. Основная проблема находится в методе Evict, где мы полным перебором ищем элемент, который будет вытеснен из кэша. Займёмся оптимизацией!
Разобьём наши элементы на группы по частоте использования. В каждой группе упорядочим все наши элементы в виде списка в порядке добавления от более раннего к более позднему. По вертикали будем располагать частотные группы, а по горизонтали будем располагать элементы в каждой группе (квадраты обозначают частотные группы, а круги - элементы, где слева записан ключ, а справа - значение):
Посмотрим, как будет изменяться структура под воздействием различных операций. Операция очистки кэша очевидна. Поэтому рассмотрим оставшиеся операции (далее красным цветом будем показывать удаление вершины или группы, а синим - добавление):
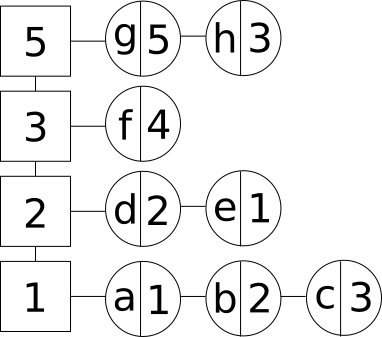
Элементы LFU кэша
- Операция удаления элемента из кэша. В данном случае мы удаляем элемент из частотной группы. Если элемент являлся последним в группе, то удаляем и данную частотную группу:
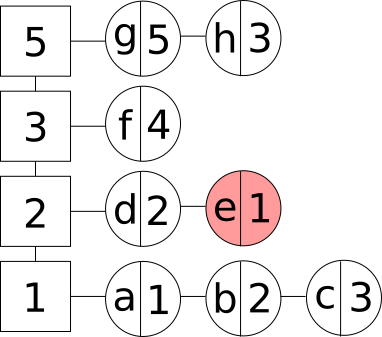
Удаление элемента из LFU кэша
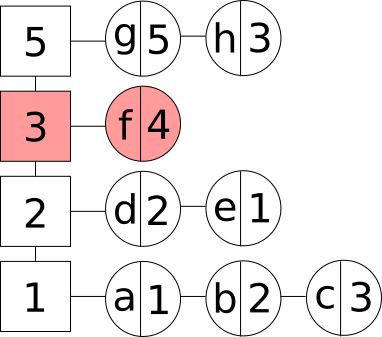
Удаление последнего элемента группы из LFU кэша
- Операция добавления нового элемента, если кэш содержит меньше элементов, чем максимально допустимое значение. В данном случае добавляется новый элемент в конце списка в группу элементов с частотой обращения равной единице:

Добавление элемента в LFU кэш
- Операция добавления нового элемента, если кэш содержит максимально допустимое количество элементов. В данном случае удаляется элемент, который находится в списке первым в группе с самой низкой частотой обращений, так как время доступа к нему меньше, чем время доступа к любому другому элементу. После удаления мы получаем структуру, в которой количество элементов меньше, чем максимально допустимое. А значит верно то, что описано в пункте выше:
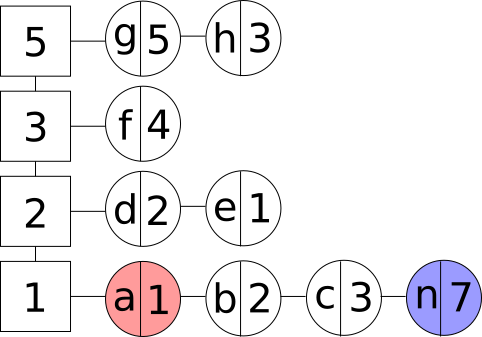
Добавление элемента с вытеснением в заполненный LFU кэш
- Операция обновления существующего элемента. Новое значение элемента при этом может быть любым, так как оно не влияет на сортировку элементов. Заметим, что если элемент был последним в группе, то данная группа удаляется. При необходимости создаётся новая частотная группа:
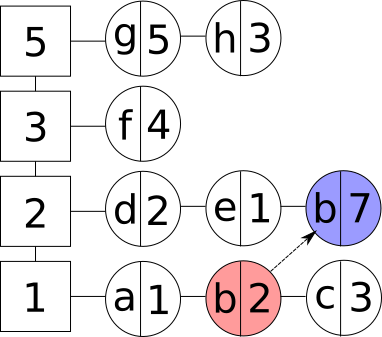
Обновление элемента в LFU кэше
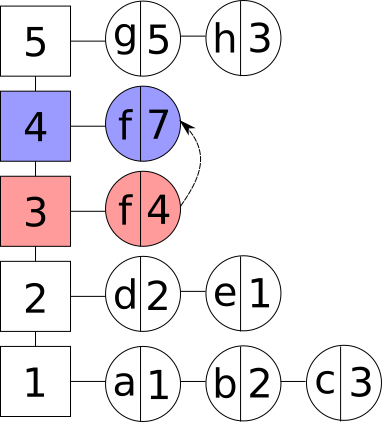
Обновление элемента и частотной группы в LFU кэше
- Операция получения значения по ключу. Данная операция эквивалентна операции обновления существующего элемента с сохранением его исходного значения.
Осталось научиться быстро находить элемент в списке по ключу. Для этого будем хранить для каждого ключа ссылку на нужный элемент. Для быстрого поиска частотной группы, также будем хранить для каждой частоты ссылку на соответствующую частотную группу.
Перепишем методы очистки и удаления элемента из кэша:
Методы добавления элемента (заметим, что реализация основного метода Add осталась прежней):
И метод получения элемента (реализация метода TryGet практически не поменялась):
На этом реализация LFU кэширования закончена. Мне надо прощаться, а тебе, дорогой читатель, предлагаю ознакомиться с другими разборами задач, которые могут попадаться на технических собеседованиях. До скорых встреч!