
Прывітанне, паважаны чытач!
Сённяшні пост я б хацеў пачаць са стандартнага пытання на сумоўі: “Якімі дасягненнямі на працы ты асабліва ганарышся?” Гэтае пытанне можа здзівіць ці нават абразіць, бо сёння аказваецца недастаткова проста добра выконваць свае абавязкі, гэтым трэба абавязкова ганарыцца. Але не дай інтэрв’юеру цябе заспець знянацку. Калі памяшканне прасторнае, то ў гэты момант лепш нават ўстаць з крэсла, твой монаспектакль павінен запальваць агонь у вачах. Абгарнуў на днях метад у try / catch? Не саромейся - ты ўжо асцярог кампанію ад выключнай сітуацыі! Месяц таму выправіў чарговы баг? Гэта было не проста выпраўленне, гэта было выратаванне кампаніі ад патэнцыйнага банкруцтва! І тут галоўнае не перастарацца, бо інтэрв’юер хутчэй за ўсё таксама часта наведвае сумоўя, і ўжо не раз “ратаваў кампанію ад банкруцтва”. А лепш, вядома, загадзя падрыхтавацца да гэтага пытання.
Але гэта стандартнае пытанне. А мы вернемся да нестандартнага. У папярэднім пасце мы ўжо пазнаёміліся з кэшаваннем і алгарытмам LRU выцяснення элементаў. Прапаную разгледзець наступны прыклад:
У кансолі мы пабачым "Element 'x' was not found". Такім чынам, з кэша будзе выцеснены элемент x, да якога было ў 100 разоў больш зваротаў, але LRU стратэгія ніяк гэта не ўлічвае. Гэты прыклад хоць і даволі надуманы, але ён добра ілюструе абмежаванні LRU стратэгіі. У гэтым пасце разгледзім новую стратэгію, якая будзе ўлічваць частату зваротаў да элементаў. Паехалі!
LFU (least frequently used) - стратэгія выцяснення элемента, які выкарыстоўваўся радчэй за ўсё. Пад дадзеным элементам разумеецца элемент, доступ да якога па ключы (метады дадання і атрымання значэння) ажыццяўляўся найменшую колькасць разоў. У выпадку, калі такіх элементаў некалькі, то выцясняецца элемент, доступ да якога не ажыццяўляўся даўжэй за ўсё.
Поўную рэалізацыю LFU кэша на C#, як і заўсёды, можна паглядзець на GitHub праекта coding-interview.
Ну а мы вернемся да рэалізацыі. Пачнем з самага простага варыянту. Рэалізуем абгортку вакол асацыятыўнага масіва без стратэгіі выцяснення:
Абмяжуем наш кэш максімальна дазволенай колькасцю элементаў capacity. Створым агульны лічыльнік доступу да элементаў totalAccessSteps, які будзем павялічваць пры кожным наступным доступе. Для кожнага захаванага элемента будзем захоўваць час доступу да яго accessStepsByKey і колькасць зваротаў да дадзенага элементу frequenciesByKey. Забягаючы наперад адзначым, што дадзеная рэалізацыя не з’яўляецца аптымальнай, у працэсе яна будзе палепшана.
Абнавім відавочныя аперацыі выдалення элемента і ачысткі кэша:
Разгледзім аперацыю дадання элемента ў кэш. У залежнасці ад сітуацыі могуць узнікнуць тры розных выпадку:
- Калі дадзены элемент прысутнічае ў кэшы, то абнаўляем яго значэнне, колькасць зваротаў і час доступу;
- Калі кэш утрымлівае менш элементаў, чым яго ёмістасць, то проста захоўваем новы элемент;
- Калі кэш ўтрымлівае ўжо максімальна дазволеную колькасць элементаў, то выдаляем элемент, які выкарыстоўваўся найменшую колькасць разоў. Калі такіх элементаў некалькі, то выдаляем элемент, доступ да якога ажыццяўляўся раней за ўсё. Пасля чаго дадаем новы элемент.
Аперацыя доступу да элемента па ключы таксама павінна памяняць час доступу і колькасць зваротаў да элемента, таму скарыстаемся ўжо рэалізаваным Update метадам:
Як адзначалася вышэй, такая рэалізацыя не з’яўляецца аптымальнай. Асноўная праблема знаходзіцца ў метадзе Evict, дзе мы поўным пераборам шукаем элемент, які будзе выцеснены з кэша. Зоймемся аптымізацыяй!
Разаб’ем нашы элементы на групы па частаце выкарыстання. У кожнай групе ўпарадкуем усе нашы элементы ў выглядзе спісу ў парадку дадання ад больш ранняга да больш позняга. Па вертыкалі будзем размяшчаць частотныя групы, а па гарызанталі будзем размяшчаць элементы ў кожнай групе (квадраты пазначаюць частотныя групы, а кругі - элементы, дзе злева запісаны ключ, а справа - значэнне):
Паглядзім, як будзе змяняцца структура пад уздзеяннем розных аперацый. Аперацыя ачысткі кэша відавочная. Таму разгледзім пакінутыя аперацыі (далей чырвоным колерам будзем паказваць выдаленне вяршыні або групы, а сінім - даданне):
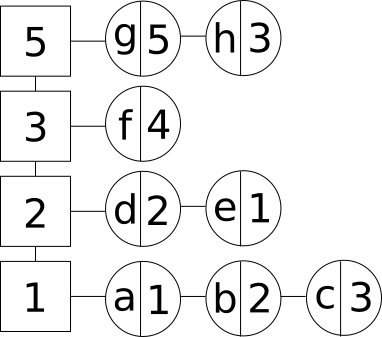
Элементы ў LFU кэшы
- Аперацыя выдалення элемента з кэша. У дадзеным выпадку мы выдаляем элемент з частотнай групы. Калі элемент з’яўляўся апошнім у групе, то выдаляем і дадзеную частотную групу:
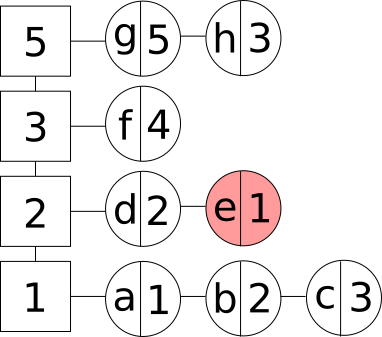
Выдаленне элемента з LFU кэша
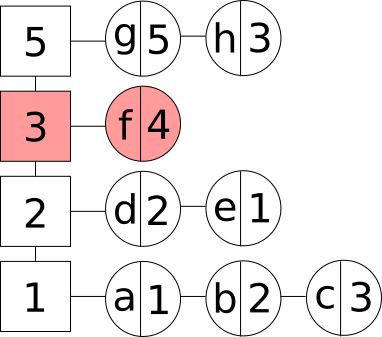
Выдаленне апошняга элемента ў групе з LFU кэша
- Аперацыя дадання новага элемента, калі кэш утрымлівае менш элементаў, чым максімальна дазволеная значэнне. У дадзеным выпадку дадаецца новы элемент у канцы спісу ў групу элементаў з частатой звароту роўнай адзінцы:

Даданне новага элемента ў LFU кэш
- Аперацыя дадання новага элемента, калі кэш змяшчае максімальна дазволеную колькасць элементаў. У дадзеным выпадку выдаляецца элемент, які знаходзіцца ў спісе першым у групе з самай нізкай частатой зваротаў, так як час доступу да яго менш, чым час доступу да любога іншага элемента. Пасля выдалення мы атрымліваем структуру, у якой колькасць элементаў менш, чым максімальна дазволеная. А значыць слушна тое, што апісана ў пункце вышэй:
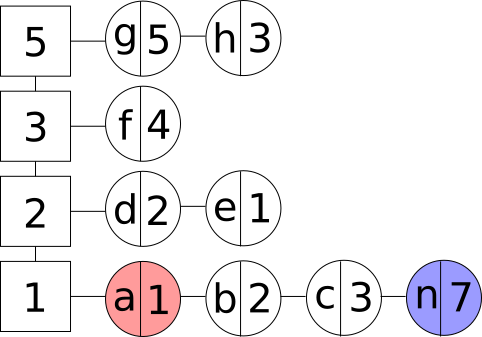
Даданне новага элемента з выцясненнем у LFU кэш
- Аперацыя абнаўлення існуючага элемента. Новае значэнне элемента пры гэтым можа быць любым, бо яно не ўплывае на сартаванне элементаў. Заўважым, што калі элемент быў апошнім у групе, то дадзеная група выдаляецца. Пры неабходнасці ствараецца новая частотная група:
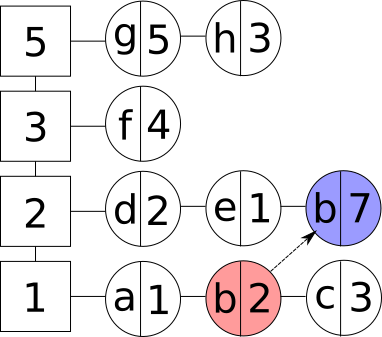
Абнаўленне элемента ў LFU кэшы
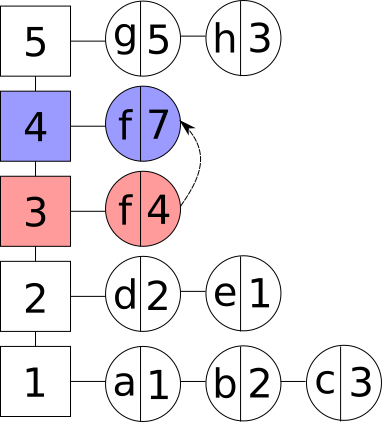
Абнаўленне элемента і частотнай групы ў LFU кэшы
- Аперацыя атрымання значэння па ключы. Дадзеная аперацыя эквівалентная аперацыі абнаўлення існуючага элемента з захаваннем яго зыходнага значэння.
Засталося навучыцца хутка знаходзіць элемент у спісе па ключы. Для гэтага будзем захоўваць для кожнага ключа спасылку на патрэбны элемент. Для хуткага пошуку частотнай групы, таксама будзем захоўваць для кожнай частоты спасылку на адпаведную частотную групу.
Перапішам метады ачысткі і выдалення элемента з кэша:
Метады дадання элемента (заўважым, што рэалізацыя асноўнага метаду Add засталася ранейшай):
І метад атрымання элемента (рэалізацыя метаду TryGet амаль не змянілася):
На гэтым рэалізацыя LFU кэшавання скончана. Мне трэба развітвацца, а табе, дарагі чытач, прапаную азнаёміцца з іншымі разборамі задач, якія могуць трапляцца на тэхнічных сумоўях. Да хуткіх сустрэч!